Current Gig

I am currently the Principal Data Scientist at Amazon.com Packaging, supporting the mission to invent sustainable packaging that delights customers, eliminates waste, and ensures products arrive intact and undamaged.
My IT interests include adoption and applications of emerging technologies; machine learning, including methods for identifying, managing and mitigating risks; big data, information management, data access and discovery; spatio-temporal data and databases; integration of biological, physical, spatio-temporal and business data; and scientific data. I'm inherently curious and cross-disciplinary in my approach, borrowing and adapting ideas from many different fields.
I'm particularly interested in integrating ML into business decision making; particularly bridging the gap from "correlation" to "causation". Amazon, like most businesses, is interested in interventions - in predicting what will happen if we "let nature take its course", and then tinkering with that outcome. This needs more than just an ML model; it needs business understanding. A fun challenge!
I was previously the Principal Data Scientist at Amazon Web Services (AWS) Professional Services, AI/ML Global Speciality Practice. I help AWS customers solve their business problems by adopting AWS technologies, fitting the technology choices and implementation to the organization, the task, the issues and associated risks. I develop new methods and approaches by combining research and practical experience, then "industrialize" them so they can be adopted and implemented by others.
In that role, I was particularly interested in understanding the risks involved in Machine Learning projects; in identifying methods to identify, assess, manage and mitigate the risks. I believe some of the public ML failures are the result of risks inherent in the technology or implementation, that were perhaps known by the implementation team but not visible to or understood by their management. In some cases, methods exist that can be adapted to avoid these occurrences. In other cases, new methods must be developed. What fun!
I was recently recognized in 7 women data scientists who made a big difference, wikipedia and long ago in IMDB.
Recent publications include:
- An AWS Big Data Blog post: Monitor data quality in your data lake using PyDeequ and AWS Glue, Joan Aoanan, Calvin Wang, and Veronika Megler (March 2, 2021). This blog shows how to use PyDeequ with Glue.
- An AWS Big Data Blog post: Testing data quality at scale with PyDeequ, Calvin Wang, Chris Ghyzel and Veronika Megler (December 30, 2020). This is the announcement blog for PyDeequ.
- A huge callout to the 3-person team for developing a Deequ version for Python! What started with my musing, "gee, I wish this was available in Python ... Hey, Chris, don't you know Scala, along with EMR & Python? How hard would it be??" turned by phases into a full-blown open-source library contribution. While I wrote none of the code, I provided the focus, consistency and cover that made it happen.
- An AWS Big Data Blog post: Detect Change Points in Your Event Data Stream Using Amazon Kinesis Data Streams, Amazon DynamoDB and AWS Lambda, Marco Guerriero and Veronika Megler (November 18, 2020). This blog focuses on "regime change", as distinct from the "data drift" case more usually discussed. For example: the 2008 market meltdown was a regime change, rather than a case of "data drift". Automatically retraining a model and launching it in production may not be the best choice in these kinds of situations.
- An AWS Big Data Blog post: Preventing Customer Churn by Optimizing Incentive Programs Using Stochastic Programming, Marco Guerriero and Veronika Megler (September 24, 2020). This blog builds on the prior Aurora/customer insights blog, replacing the dummy incentive program used there with one created using optimization.
- An AWS Machine Learning Blog post: Gain customer insights using Amazon Aurora machine learning, Veronika Megler and Vitalina Komashko (May 5 2020). This blog integrates ML into a business process to prevent (not just predict) customer churn. It focuses on using explainability of a churn prediction XGBoost model to inform Marketing and Customer Service, giving them the information to create an effective intervention to stop the churn.
- An AWS Machine Learning Blog post: Exploring images on social media using Amazon Rekognition and Amazon Athena, Veronika Megler and Chris Ghyzel (Nov 18 2019).
- An AWS Machine Learning Blog post: Optimizing portfolio value with Amazon SageMaker automatic model tuning, Scott Gregoire and Veronika Megler (Oct 2019). Another blog in the series bridging the gap between ML technology and the business. We describe a method of choosing an optimal threshold, or set of thresholds, in a classification setting. The method we describe doesn't rely on rules of thumb or generic metrics. It is a systematic and principled method that relies on a business success metric specific to the problem at hand. The method is based upon utility theory and the idea that a rational individual makes decisions so as to maximize her expected utility, or subjective value.
- An AWS Machine Learning Blog post: Exploring data warehouse tables with Machine Learning and Amazon SageMaker notebooks (May 2019). The most complex infrastructure yet: integrating Amazon SageMaker, Amazon Redshift, Amazon Glue and Amazon EMR.
- An AWS Machine Learning Blog post: Easily perform bulk label quality assurance using Amazon SageMaker Ground Truth, with Chris Ghyzel (March 2019). Check out the section 'Acting on the results', about classification bias between saxophones, crawdads and lobsters.
- An AWS Whitepaper: Managing Machine Learning Projects: Balance Potential with the Need for Guardrails (February 2019). This whitepaper discussed methods for identifying, evaluating and managing risks in machine learning projects. It provides pragmatic tools that have been tested in real world settings, such as scorecards, to bridge the communication gap between machine learning experts and the executives responsible for the business impacts of the ML models they implement.
- An AWS Machine Learning Blog post: Training models with unequal economic error costs using Amazon SageMaker, Veronika Megler and Scott Gregoire, PhD. (September 2018). "In some applications all types of prediction errors are truly equal in impact. In other applications, one kind of error can be much more costly or consequential than another - measured in absolute or relative terms, in dollars, time, or something else. For example, predicting someone does not have breast cancer when they do (a false negative error) will, according to medical estimates, likely have much greater cost or consequences than the reverse error. We may even be willing to tolerate more false positive errors if we sufficiently reduce the false negatives to compensate. In this blog post, we address applications with unequal error costs with the goal of reducing undesirable errors while providing greater transparency to the trade-offs being made."
- An AWS Machine Learning Blog post: Access Amazon S3 data managed by AWS Glue Data Catalog from Amazon SageMaker notebooks (August 2018).
- An AWS Big Data Blog post: Improve the Operational Efficiency of Amazon Elasticsearch Service Domains with Automated Alarms Using Amazon CloudWatch (March 2018).
- An AWS Database Blog post: Analyzing Amazon Elasticsearch Service Slow Logs Using Amazon CloudWatch Logs Streaming and Kibana (March 2018).
- An AWS Management Tools Blog post: How to Export EC2 Instance Execution Logs to an S3 Bucket Using CloudWatch Logs, Lambda, and CloudFormation (November 2017).
- An AWS Compute Blog post: How to Provision Complex On Demand Infrastructures by Using Amazon API Gateway and AWS Lambda, co-authored with Ben Eichorst (September 2017).
- An AWS Big Data Blog post: Integrating IoT Events into Your Analytic Platform (September 2016).
- An AWS Big Data Blog post: Anomaly Detection using PySpark, Hive and Hue on Amazon EMR (March 2016).
- And in the "Ancient History" category, There and Back Again: A Case History of Writing The Hobbit, Refractory, Volume 27, Issue 1. (Published 2016, written & presented in 2014).
From July 2014 to August 2015 I was a post-doctoral fellow in Computer Science at the Maseeh College of Engineering & Computer Science, Portland State University, in Portland Oregon. Just prior, from Fall 2009 to August 2015, I was a PhD candidate, working with Professor Dave Maier at Portland State University, and with the Center for Margin Observation and Prediction (CMOP) (part of OHSU). That work is described in the section 'PhD Work', below.
![]() or contact me at:
or contact me at: 
(Even Older) Past Lives (and, yes, including The Hobbit)
My prior industry position was Executive IT Architect at IBM, which I left to pursue my Masters and PhD. Here are links for: a) a summary of recent accomplishments and b) a list of my industry publications.
My 15 minutes of fame (well, it's well over 30 minutes by now) are documented in many places, including: Tolkien Gateway (which references a parody of the game I didn't know about), World of Spectrum (with a picture I have no memory of), and a Wikipedia entry (none of which I wrote). There's even a walk-through, here.
As of "the day I last checked", "The Hobbit (1982)" was the second most downloaded item in the Internet Archive's Historical Software Collection, where you can 'play it again' in an emulator. And someone spent far longer than it took Phil and me to code it on reverse-engineering it (from the bytecode, no less; the original was in Z80 assembler and as far as I know the source code was never released) and exposing the innards (Wilderland).

I hereby apologize for making Thorin spend so much of his time singing about gold... Too short a character action list, you see...
A random, unscientific sampling of the (extensive) media coverage includes:
- CNN Great Big Story, The Hunt for the Hobbit Hero, September 2017. The series it's part of, 8 Bit, has been nominated for an Emmy! The episode has a couple of unfortunate errors in it, the most egregious of which is, to my mind, Fred Milgrom stating that Phil was the programmer and I adapted the book into the game. In reality, I wrote exactly half the code (according to an outstanding analysis of our differing programming styles performed by Wilderland's author). My design and code includes what today you'd call the game engine, physics engine, and non-player characters - and, sadly, many of the bugs. Phil designed and wrote Inglish, the interface and graphics engines. The modular design allowed us to have a clean interface between the two "halves" (from a code perspective) of the game.
- Interview on storytelling as part of Luke Jackson's interesting PhD research into educational games.
- Author of '80s classic The Hobbit didn't know game was a hit (what can I say, I was busy!)
- The Digital Antiquarian
- "The Making of the Hobbit", in Retro Gamer Edition 101; also an earlier retrospective describing the game as "Characters that moved about by themselves, did things for themselves. it was like proper artificial intelligence of the sort only seen on BBC Micro Live with Fred Harris." (along with a little too much anger taken out on poor Thorin).
- Interview for the 1980's episode of the Australian Broadcasting Commission's "Short History of Video Games", with Dan Golding
... and I even wrote a recent blog article for the Australian Center for the Moving Image, Ruminations on The Hobbit Fandom. Here is their profile of me. There's also a paper I presented at the 'Born Digital and Cultural Heritage Conference', ACMI, Melbourne Australia, in June 2014.
My PhD Work (Computer Science)
I received my PhD in June, 2014, from Portland State University in Oregon. My dissertation topic is "Ranked Similarity Search of Scientific Datasets: An Information Retrieval Approach". My thesis committee consisted of:
- Dave Maier (Chair), Maseeh Professor (CS), Portland State University, ACM Fellow
- Alon Halevy, Head of Structured Data Research, Google Inc., ACM Fellow
- Lois Delcambre, Professor (CS), Portland State University
- Jiunn-Der (Geoffrey) Duh, Professor (Dept. of Geography), Portland State University
My scholarly publication list is here.
My dissertation work was a system I called "Data Near Here".
"Data Near Here"
"Data Near Here" applies ideas from the field of cognitive science and spatial cognition, Information Retrieval and Internet search to massive archives of scientific datasets. I address the following problem: with the explosion of data collected by scientists and stored in many files, many formats, many naming conventions, how do scientists find data that matches their research needs?
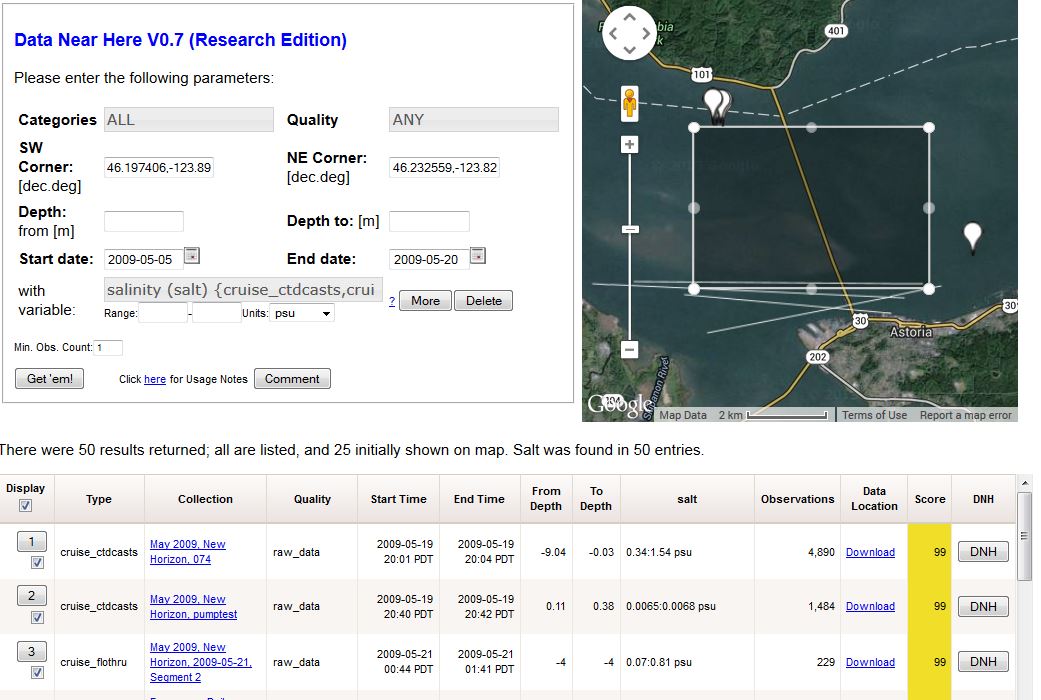
I use a running example of a scientist searching for salinity observations collected in of May 2009, near the Astoria-Megler bridge. A screenshot of DNH running over CMOP's archive can be seen below. Note that in this case, there are no exact matches for the scientist's search terms as formulated; given no exact matches, the tool presents an ordered list with the "closest" matches at the top.
Similar in concept to the way an Internet text search engine operates, I focus on providing a set of results ranked by 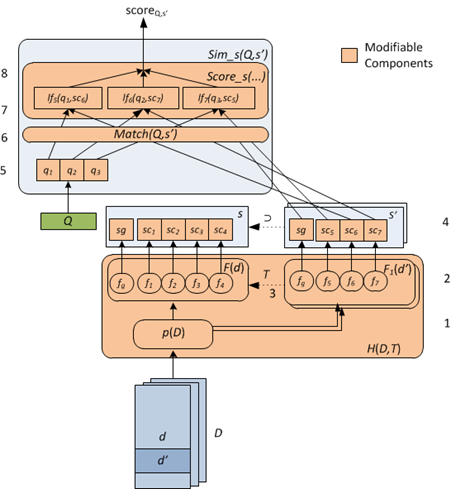 similarity to a scientist's search; however, rather than text webpages, my users are searching for scientific (primarily numeric) data. I assume that after reviewing the search results, the scientist will wish to download, visualize or otherwise process selected datasets using other tools. Thus, the search engine is complementary to existing analysis and visualization technologies.
similarity to a scientist's search; however, rather than text webpages, my users are searching for scientific (primarily numeric) data. I assume that after reviewing the search results, the scientist will wish to download, visualize or otherwise process selected datasets using other tools. Thus, the search engine is complementary to existing analysis and visualization technologies.
In later work, we started testing these concepts on genomic data, in a system we called "Data Like This".
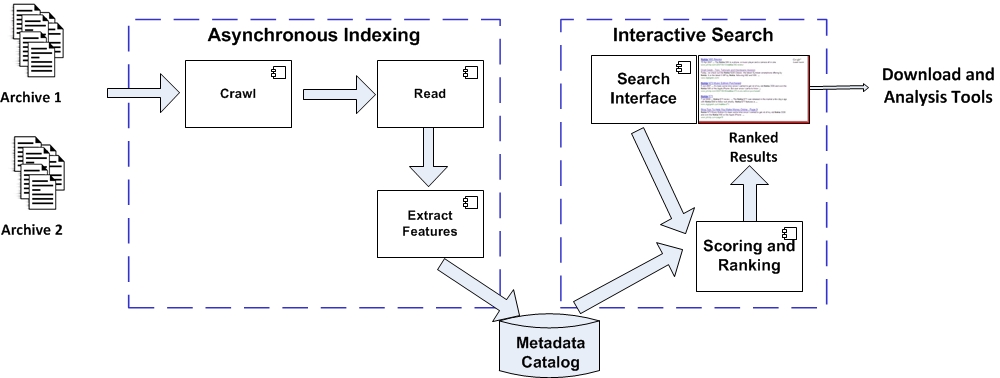
How it Works:
A set of crawlers scan an archive of datasets, asynchronously. I create a brief summary of the contents of each dataset, modeled on the internal mental model scientists have of their data, and store the summary in a metadata catalog using a simple, consistent abstraction. The current prototype handles several different file types, and the scanning process can be easily extended to handle additional file types and formats.
The user enters search criteria into a UI. (Note: "I am not a UI designer, and this is not the topic of my research.") A search engine searches over the metadata and returns ranked search results
of the "closest matches" to the query, in real-time. Searches can include location, time, variable names of interest, or desired ranges for the data values. The results are displayed in a list (and, if geolocation information is available, on a map), along with brief summary information.
The results can be downloaded for analysis or plotted in linked data analysis or visualization tools. A link leads to a page that shows the full metadata available for that dataset, thus providing the scientist with additional information upon which to make analysis decisions, if desired.
Publications
"Data Near Here" is described in the following publications:
- The best high-level overview of the work is: Megler, V.M. and Maier, D.:
Data Near Here: Bringing Relevant Data Closer to Scientists.
In: Computing in Science and Engineering, March 2013, Volume 15, No. 3. A preprint version can be downloaded here by permission.
- Two user studies that show the effectiveness of the approach are described in Are Datasets Like Documents?: Evaluating Similarity-Based Ranked Search Over Scientific Data.
In: TKDE: Transactions on Knowledge and Data Engineering, Volume 27, Issue 1, pp 32-45. January 1, 2015. An author's copy can be downloaded here by permission,
and the referenced appendices are here.
- "Data Like This: Ranked Search of Genomic Data", V.M. Megler, David Maier, Daniel Bottomly, Libbey White, Shannon McWheeney, Beth Wilmot; workshop paper, ExploreDB 2015, Melbourne, Australia, May 2015. A local copy is available (by permission) here.
-
 Demonstrating "Data Near Here": Scientific Data SearchV.M. Megler, David Maier
Demonstrating "Data Near Here": Scientific Data SearchV.M. Megler, David Maier
SIGMOD '15 Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, 2015
- Scalability and performance challenges, based on the current prototype implementation, are discussed here: Maier, D., Megler, V.M., Tufte, K.:
Challenges for Dataset Search (keynote).
Presented at the International Conference on Database Systems for Advanced Applications, Bali, Indonesia April (2014).
Lecture Notes in Computer Science Volume 8421, 2014, pp 1-15. It can also be downloaded here (by permission).
- The issues that result from "variable diversity" - the many things a single variable may be named - are described in: Megler, V.M. (Supervised by David Maier): Taming the Metadata Mess. In: ICDE Brisbane Workshops (PhD Symposium), April, 2013. It can also be downloaded here (by permission).
The poster (which has additional diagrams/material not in the paper) is here.
- An early version of the underlying model is described in:
When big data leads to lost data, V. M. Megler, David Maier
PIKM '12 Proceedings of the 5th Ph.D. workshop on Information and knowledge, 2012. Winner of PIKM "Best Paper" award. (The updated model is described in my dissertation.)
- How it fits in the context of the archive it was originally built for is described in: Maier, D., Megler, V.M., Baptista, A., Jaramillo, A., Seaton, C., Turner, P.: Navigating Oceans of Data. In: Ailamaki, A. and Bowers, S. (eds.) Scientific and Statistical Database Management. Lecture Notes in Computer Science, Volume 7338, pp. 1-19. Springer Berlin / Heidelberg (2012). The original publication is available at SpringerLink,
or can be downloaded here (by permission)..
- Megler, V.M., Maier, D.: Finding Haystacks with Needles: Ranked Search for Data Using Geospatial and Temporal Characteristics.
In: Bayard Cushing, J., French, J., and Bowers, S. (eds.) Lecture Notes in Computer Science, Volume 6809, pp. 55-72. Springer Berlin / Heidelberg (2011).
The original publication is available at SpringerLink,
or can be downloaded here (by permission).
Selectivity: 34% acceptance rate for long papers.
- "Data Near Here: Ranked Geospatial-Temporal Search of Scientific Data", V.M. Megler and David Maier, presented at Symposium on Space-Time Integration in Geography and GIScience, AAG 2011, April 2011
- "Data Near Here: Ranked Geospatial-Temporal Search of Scientific Data (Take 1)", Veronika Megler and David Maier, GIS In Action 2011, March 2011
... and, of course, at great length in my dissertation: "Ranked Similarity Search of Scientific Datasets: An Information Retrieval Approach" (of which sections, surprisingly, strongly resemble the above listed papers. But there is additional content there, too). [local copy]
A patent "A Search Tool that Utilizes Numerical Scientific Metadata Matched Against User-Entered Parameters Edit", United States Patent US8560531 B2 was issued on issued October 15, 2013 (filed July 1, 2011). Inventors: Veronika Megler, David Maier; Joint IBM/Portland State University.
Later 'Data Near Here' Activities
Data Near Here is in production at CMOP, for use by registered users only. It will be opened to outside users in the (hopefully near) future (reasons for the delay can be found here). The CMOP production implementation currently focuses primarily on CMOP's own data archive. Data from other archives was to be searchable via this implementation in the future, and development instances of the system provided that capability.
A research prototype was available (last time I checked) here.
The interactive portion is written in PHP, Javascript, JQuery, accessing a
PostgreSQL database. The crawlers are in Python. Technologies were chosen for ease of prototyping and to fit in with CMOP's standards, and may not, in fact, be the best choices for this kind of application.
We also explored application of the same ideas and concepts to genomics data ("Data Like This"), and developed an early proof-of-concept.
"Portland Observatory"
I also contributed to the Portland Observatory project. This research project intended to explore how one might architect and build an observatory that understands and adapts to the wide variety of data gathered or otherwise available in a single domain. Our local city of
Portland, Oregon, was a laboratory and example within which to explore these concepts.
One use case is described in Guiding Data-Driven Transportation Decisions.
In BDUIC 2014, the Big Data and Urban Informatics Workshop,
UIC, Chicago, IL, August 11-12, 2014.
A second use case is described in Improving Data Quality in Intelligent Transportation Systems, Tech Report S23204, August 2015 (Megler, Tufte & Maier).
"Data Near Here" applies ideas from the field of cognitive science and spatial cognition, Information Retrieval and Internet search to massive archives of scientific datasets. I address the following problem: with the explosion of data collected by scientists and stored in many files, many formats, many naming conventions, how do scientists find data that matches their research needs?
I use a running example of a scientist searching for salinity observations collected in of May 2009, near the Astoria-Megler bridge. A screenshot of DNH running over CMOP's archive can be seen below. Note that in this case, there are no exact matches for the scientist's search terms as formulated; given no exact matches, the tool presents an ordered list with the "closest" matches at the top.
Similar in concept to the way an Internet text search engine operates, I focus on providing a set of results ranked by similarity to a scientist's search; however, rather than text webpages, my users are searching for scientific (primarily numeric) data. I assume that after reviewing the search results, the scientist will wish to download, visualize or otherwise process selected datasets using other tools. Thus, the search engine is complementary to existing analysis and visualization technologies.
In later work, we started testing these concepts on genomic data, in a system we called "Data Like This".
How it Works:
A set of crawlers scan an archive of datasets, asynchronously. I create a brief summary of the contents of each dataset, modeled on the internal mental model scientists have of their data, and store the summary in a metadata catalog using a simple, consistent abstraction. The current prototype handles several different file types, and the scanning process can be easily extended to handle additional file types and formats.
The user enters search criteria into a UI. (Note: "I am not a UI designer, and this is not the topic of my research.") A search engine searches over the metadata and returns ranked search results of the "closest matches" to the query, in real-time. Searches can include location, time, variable names of interest, or desired ranges for the data values. The results are displayed in a list (and, if geolocation information is available, on a map), along with brief summary information. The results can be downloaded for analysis or plotted in linked data analysis or visualization tools. A link leads to a page that shows the full metadata available for that dataset, thus providing the scientist with additional information upon which to make analysis decisions, if desired.
Publications
"Data Near Here" is described in the following publications:
- The best high-level overview of the work is: Megler, V.M. and Maier, D.: Data Near Here: Bringing Relevant Data Closer to Scientists. In: Computing in Science and Engineering, March 2013, Volume 15, No. 3. A preprint version can be downloaded here by permission.
- Two user studies that show the effectiveness of the approach are described in Are Datasets Like Documents?: Evaluating Similarity-Based Ranked Search Over Scientific Data. In: TKDE: Transactions on Knowledge and Data Engineering, Volume 27, Issue 1, pp 32-45. January 1, 2015. An author's copy can be downloaded here by permission, and the referenced appendices are here.
- "Data Like This: Ranked Search of Genomic Data", V.M. Megler, David Maier, Daniel Bottomly, Libbey White, Shannon McWheeney, Beth Wilmot; workshop paper, ExploreDB 2015, Melbourne, Australia, May 2015. A local copy is available (by permission) here.
-
Demonstrating "Data Near Here": Scientific Data SearchV.M. Megler, David Maier
SIGMOD '15 Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, 2015 - Scalability and performance challenges, based on the current prototype implementation, are discussed here: Maier, D., Megler, V.M., Tufte, K.: Challenges for Dataset Search (keynote). Presented at the International Conference on Database Systems for Advanced Applications, Bali, Indonesia April (2014). Lecture Notes in Computer Science Volume 8421, 2014, pp 1-15. It can also be downloaded here (by permission).
- The issues that result from "variable diversity" - the many things a single variable may be named - are described in: Megler, V.M. (Supervised by David Maier): Taming the Metadata Mess. In: ICDE Brisbane Workshops (PhD Symposium), April, 2013. It can also be downloaded here (by permission). The poster (which has additional diagrams/material not in the paper) is here.
- An early version of the underlying model is described in:
When big data leads to lost data, V. M. Megler, David Maier
PIKM '12 Proceedings of the 5th Ph.D. workshop on Information and knowledge, 2012. Winner of PIKM "Best Paper" award. (The updated model is described in my dissertation.) - How it fits in the context of the archive it was originally built for is described in: Maier, D., Megler, V.M., Baptista, A., Jaramillo, A., Seaton, C., Turner, P.: Navigating Oceans of Data. In: Ailamaki, A. and Bowers, S. (eds.) Scientific and Statistical Database Management. Lecture Notes in Computer Science, Volume 7338, pp. 1-19. Springer Berlin / Heidelberg (2012). The original publication is available at SpringerLink, or can be downloaded here (by permission)..
- Megler, V.M., Maier, D.: Finding Haystacks with Needles: Ranked Search for Data Using Geospatial and Temporal Characteristics. In: Bayard Cushing, J., French, J., and Bowers, S. (eds.) Lecture Notes in Computer Science, Volume 6809, pp. 55-72. Springer Berlin / Heidelberg (2011). The original publication is available at SpringerLink, or can be downloaded here (by permission). Selectivity: 34% acceptance rate for long papers.
- "Data Near Here: Ranked Geospatial-Temporal Search of Scientific Data", V.M. Megler and David Maier, presented at Symposium on Space-Time Integration in Geography and GIScience, AAG 2011, April 2011
- "Data Near Here: Ranked Geospatial-Temporal Search of Scientific Data (Take 1)", Veronika Megler and David Maier, GIS In Action 2011, March 2011
... and, of course, at great length in my dissertation: "Ranked Similarity Search of Scientific Datasets: An Information Retrieval Approach" (of which sections, surprisingly, strongly resemble the above listed papers. But there is additional content there, too). [local copy]
A patent "A Search Tool that Utilizes Numerical Scientific Metadata Matched Against User-Entered Parameters Edit", United States Patent US8560531 B2 was issued on issued October 15, 2013 (filed July 1, 2011). Inventors: Veronika Megler, David Maier; Joint IBM/Portland State University.
Later 'Data Near Here' Activities
Data Near Here is in production at CMOP, for use by registered users only. It will be opened to outside users in the (hopefully near) future (reasons for the delay can be found here). The CMOP production implementation currently focuses primarily on CMOP's own data archive. Data from other archives was to be searchable via this implementation in the future, and development instances of the system provided that capability.
A research prototype was available (last time I checked) here. The interactive portion is written in PHP, Javascript, JQuery, accessing a PostgreSQL database. The crawlers are in Python. Technologies were chosen for ease of prototyping and to fit in with CMOP's standards, and may not, in fact, be the best choices for this kind of application.
We also explored application of the same ideas and concepts to genomics data ("Data Like This"), and developed an early proof-of-concept.
I also contributed to the Portland Observatory project. This research project intended to explore how one might architect and build an observatory that understands and adapts to the wide variety of data gathered or otherwise available in a single domain. Our local city of Portland, Oregon, was a laboratory and example within which to explore these concepts.
One use case is described in Guiding Data-Driven Transportation Decisions. In BDUIC 2014, the Big Data and Urban Informatics Workshop, UIC, Chicago, IL, August 11-12, 2014.
A second use case is described in Improving Data Quality in Intelligent Transportation Systems, Tech Report S23204, August 2015 (Megler, Tufte & Maier).
Other Projects
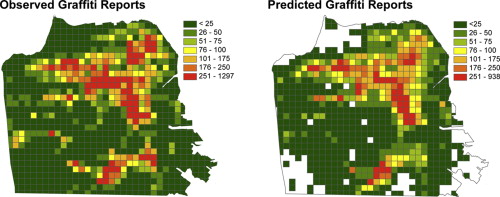
I am involved in other "random" (fun) research-related activities. They include:
- A publication on Spatial analysis of graffiti in San Francisco. Megler, V., Banis, D. and Chang, H. 2014. Journal of Applied Geography. 54, (Oct. 2014), 63-73. An author's copy can be downloaded here (by permission).
- Third prize in a national drone competition sponsored by AUVSI (Association for Unmanned Vehicle Systems Intnl), as the data geek of the "Three Chicks and a Drone".
- BORES ME NO MORE (Based On Repeated Experience, System for Modification of Expression and Negating Overload from Media and Optimizing Referential Efficiency), my "other" patent: an idea I came up with during a phone meeting when Jennifer went off again ...
 I originally fantasized about peaceful nature sounds playing until someone asked me a question, whereupon the system would play a short tape to the other participants of me saying, "I'm sorry, I was talking to the mute button", while showing me a transcribed version of immediately preceding context so I could formulate my response. My co-author came up with the excellent title and acronym. (Names in alphabetical order, by IBM standard. Getting them to keep the title was tough.)
I originally fantasized about peaceful nature sounds playing until someone asked me a question, whereupon the system would play a short tape to the other participants of me saying, "I'm sorry, I was talking to the mute button", while showing me a transcribed version of immediately preceding context so I could formulate my response. My co-author came up with the excellent title and acronym. (Names in alphabetical order, by IBM standard. Getting them to keep the title was tough.) - Historical research, leading to me authoring 2 Wikipedia pages: J.G. Megler (Washington State Senator and Speaker of the House) and the ghost "company town" of Brookfield, Washington (with additional publications planned).